ACID in EloqKV : Atomic Operations

In the previous blog, we discussed the durable feature of EloqKV and benchmarked the write performance of EloqKV with the Write-Ahead-Log enabled. In this blog, we will continue to explore the transaction capabilities of EloqKV and benchmark the performance of distributed atomic operations using the Redis MULTI EXEC commands.
In this blog, we evaluate small scale clusters to show the behavior of EloqKV accross servers. Scalability in a larger scale cluster with different number of servers will be evaluated at a later blog. All benchmarks were conducted on AWS (region: us-east-1) EC2 instances, with Ubuntu 22.04. In all tests, we use EloqKV version 0.7.4.
Transaction in EloqKV
Fifteen years ago, the esteemed database researcher and Turing Award Winner Mike Stonebraker famously wrote an article in Communications of the ACM declaring, "No ACID Equals No Interest" for enterprise users. Unfortunately, due to the high costs associated with distributed transactions, many distributed databases avoid full transaction support in favor of better performance. For example, while Redis supports limited transaction operations in single-node mode, it does not support transactions across servers in a cluster.
Thanks to our Data Substrate architecture, EloqKV is a fully ACID-compliant database. In addition to offering durability, which was discussed in a previous blog post, EloqKV's transaction capabilities support the Redis WATCH, MULTI, DISCARD, and EXEC commands even in a cluster.
In this blog, we focus on benchmarking the MULTI and EXEC commands for PUT/GET operations—specifically, performing a series of read and write operations atomically across a cluster of servers. We believe this workload provides valuable insights into the costs associated with distributed transactions. Although EloqKV also supports WATCH, DISCARD, and Lua scripting, creating standard representative test cases for these features is more challenging.
In EloqKV, by default, the ACI (Atomicity, Consistency, Isolation) part of ACID is always enabled. No configuration changes are required to enable MULTI and related commands in a cluster. EloqKV supports different levels of isolation, with the default being Repeatable Reads, which is the isolation level used in the experiments discussed in this blog.
In Repeatable Reads isolation level, reads and writes are about the same complexity. For read requests, each key must be read and then validated during the transaction commit phase to ensure that no modification happened in between reading and commiting. For write requests, a write lock must be acquired for each key and then released at the commit phase. Both require extra round-trips to accomplish and thus more expensive than non-transactional operations. In EloqKV, a single-key operation is executed as a transaction and will not incur additional overhead, regardless of the isolation level.
Experiments
In the first experiment, we compare EloqKV and Redis in batch mode across different workloads. We focus on two batch modes:
-
Pipeline: In this mode, the client sends multiple commands to the server without waiting for responses to previous commands. The server processes these commands sequentially and returns all the responses at once. This batching approach significantly reduces network communication overhead, especially when executing many commands. Notice that each command in the pipeline is executed independently, with potentially other commands executed in between. However, we do enforce that the commands for any given key is executed in the order they appear in pipeline.
-
MULTI / EXEC: This mode ensures that a group of commands is executed as a single atomic operation, meaning either all commands are executed or none are. Please note that the Redis
MULTI/EXECcommand withoutWATCHnormally cannot fail because Redis execute commands in a single thread on a single server, whereas EloqKV, being multi-threaded, can fail a transaction and roll back due to concurrent transaction conflicts.
Redis does not support Multi Exec in cluster mode if keys in a single batch do not fall on the same shard. To work around this, users must use hashtags to ensure keys involved in a transaction are located on the same shard. This can be cumbersome and often cause load imbalance. Moreover, for Redis, Pipeline support in cluster mode is client dependent. It is not a feature supported on all Redis clients. EloqKV, on the other hand, does not have these limitations. Transactions and Pipelines work on a cluster of nodes just as on a single node. Though EloqKV does support hashtags to colocate keys in order to reduce network overhead.
In the following experiments, EloqKV operates in pure memory mode, with persistent storage and write-ahead-log (WAL) disabled.
Hardware and Software Specification
Server Machine:
| Service type | Node type | Node count |
|---|---|---|
| EloqKV 0.7.4 | c7g.8xlarge | 1 |
| EloqKV 0.7.4 Cluster | c7g.8xlarge | 3 |
| Redis 7.2.5 | c7g.8xlarge | 1 |
| Client eloq-bench | c6gn.8xlarge | 1 |
Experiment:
We developed a new benchmarking tool, eloq_benchmark, specifically to test the transaction performance of Redis and EloqKV, as memtier_benchmark does not support Multi Exec. You can download eloq_benchmark here
We run eloq_benchmark with the following configuration:
eloq_benchmark --h $server_ip --p $server_port --numKeys=$keynum --numConnections=$conn --getRatio=$ratio --opType=$optype --batchSize=$batchsize --numTestOps=$testops
-
--numKeys: Number of entries, which is set to 1000000. -
--numConnections: Number of concurrent connnections, which is set to 256 for single-node and 768 for three-node cluster. -
--numTestOps: Number of test operations, which is set to 5000000. -
--getRatio: Set it to 0 for write-only workload, 0.5 for mixed workload and 1 for read-only workload. -
--opType: Set batch mode, set it topipelinefor pipeline mode, set it totxforMutilExecatomic mode. -
--batchSize: Number ofPut/Getoperations on random keys in a batch, which we set to 6.
Results
Below are the performance results of batch mode of Redis and EloqKV among various workload. Note that the number of operations of PUT/GET in a batch is fixed at 6.
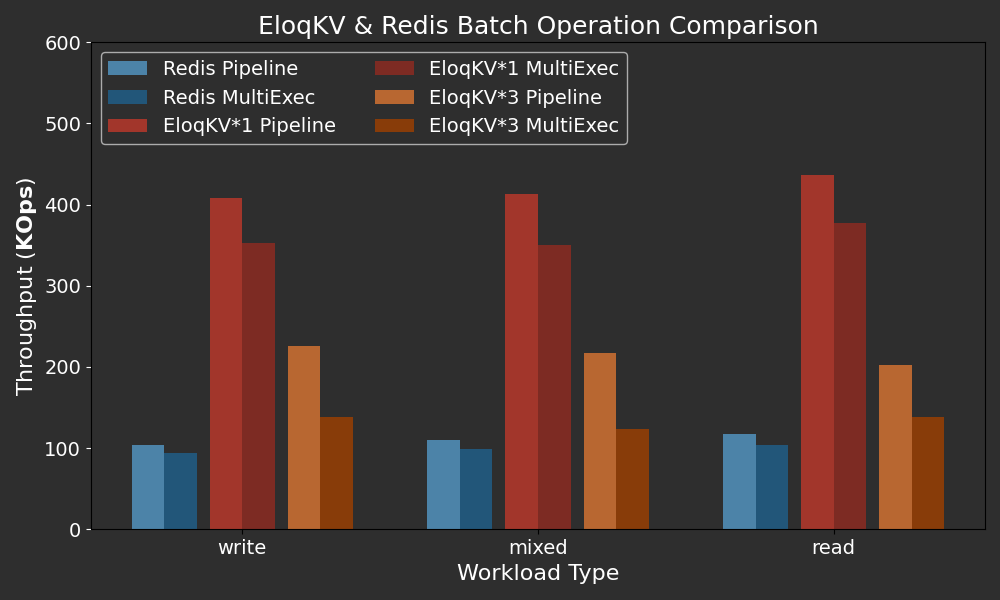
X-axis: Represents the different workload types (read/write/mixed) used in the benchmark, simulating a range of real-world scenarios.
Y-axis: Throughput in Thousand OPS (Operations Per Second) for the batches. This number should be multiplied by 6 (batch size) to obtain the total KV operations.
On a single node, EloqKV significantly outperforms Redis in both pipeline and Multi Exec modes. With a fixed batch size of 6 keys, EloqKV achieves a throughput exceeding 200 million KV operations per second (KPS) in both modes on a single server. Multi Exec is slower than Pipeline due to additional book-keeping needed for atomic operations.
The throughput of a three-node EloqKV cluster is lower than that of a single-node EloqKV. In Pipeline mode, this is because of the additional network round trips. For Multi Exec, additional operations are needed for lock acquisition and releasing. Even so, the performance is quite respectable.
Evaluate the Impact of Batch Size
Transaction size affects the efficiency of distributed transactions. In this experiment, we test eloq_benchmark with batch sizes ranging from 1 to 6.
Result
Below are the performance results of EloqKV Multi Exec command with different batch size among various workload.
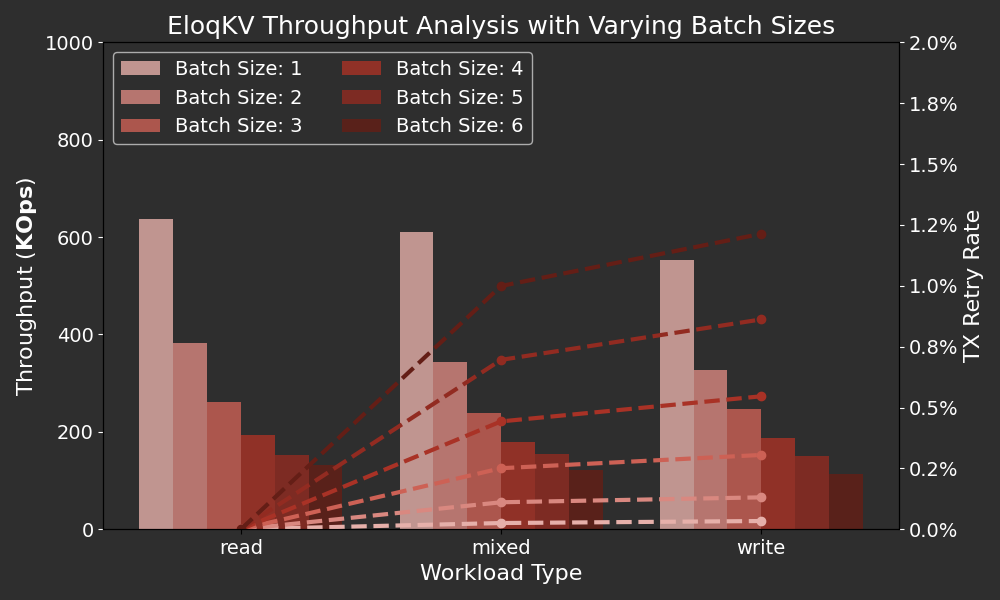
X-axis: Represents the different workload types (read/write/mixed) used in the benchmark, simulating a range of real-world scenarios.
Left Y-axis: Throughput in Thousand OPS (Operations Per Second), shown as the bars.
Right Y-axis: Percentage of Transaction Retries, shown as the dashed lines.
As expected, EloqKV’s transaction throughput decreases as the batch size increases. This is because larger batch sizes introduce additional work. Notice that the total KV operations carried out in the cluster must be multiplied by the batch size. Currently, EloqKV does not perform "query optimization" within a transaction. To guarantee transactional semantics, the operations in a batch are executed sequentially. In the future, we may optimize this by allowing some operations within a batch to be executed in parallel.
In our workload, we selected several random keys from a range to perform PUT/GET operations. As mentioned earlier, the key range was set to 1,000,000 in all experiments. We observed that transaction retries increase with larger batch sizes in both mixed and write-only workloads. This is due to the higher likelihood of transaction conflicts as the batch size grows. Reducing the level of concurrency or expanding the key range can help mitigate these conflicts. Additionally, the more concurrent writes, the more likely conflicts will occur. For read-only workloads, no transaction conflicts arise, so no transaction retries occurred.