EloqKV Clustering

In our previous blog, we benchmarked EloqKV to evaluate it as an in-memory cache, focusing on single-node performance. In this blog, we shift our attention to Eloq clustering and discuss why it provides a fundmentally better solution.
In this blog, we evaluate small scale clusters to show the behavior of EloqKV accross servers. Scalability in a larger scale cluster with different number of servers will be evaluated at a later blog. All benchmarks were conducted on AWS (region: us-east-1) EC2 instances running Ubuntu 22.04. Workloads were generated using the memtier-benchmark tool.
KV Store Clustering
For most real-world applications that require a key-value (KV) cache, even single-threaded Redis is often sufficiently fast. In fact, the limiting factor is usually memory capacity. As a result, KV caches are commonly deployed in cluster mode.
Most KV caches support horizontal scaling and operate in cluster mode by partitioning data into slots and distributing them across shards. In a horizontally scaled cluster, performance and capacity can generally scale almost linearly, though load imbalances and failure cases can introduce challenges. To achieve this scalability, developers must understand the concepts of slots, shards, and tags. And the so called cluster-aware clients need to know the cluster topology to direct requests to the correct server.
Clustering for KV cache is fraught with pitfalls, not the least is because nodes in a cluster may fail. External tools such as Sentinel, Twemproxy, Dragonfly Cloud services are often required to monitor cluster health and handle failovers. How these tools interact with clients are often not well specified. Additionally, a KV cache cluster behaves differently than a single node server. For instance, the "MULTI / EXEC" commands do not work in a clustered environment.
The fundmental issue is that many KV caches were initially designed as single-node servers, with clustering added later as a bolt-on feature. For example, Redis was released on May, 2009, while Sentinel support arrived in Redis 2.8 in December 2013. Redis Cluster became a stable feature only with Redis 3.0 in April 2015. The same can be said for many other KV stores.
Why EloqKV Clustering is Different
EloqKV eliminates these issues by being designed as a fully distributed transactional database from the start. While it can function as a single-node server and use various clustering tools for horizontal scalability, it is also capable of operating as a cluster without exposing cluster details to clients. Clients can interact with any node in an EloqKV cluster without worrying about which server holds the key, how data is sharded, if there’s a failure in the cluster, or whether the cluster is reconfiging to dynamically increase or reduce capacity. This simplifies the development process and reduces the need for cluster-aware clients.
Obviously, making this process transparent to the client and shielding cluster details has cost. In particular, a node redirecting requests will incur an extra network round trip. Therefore, we do allow enabling a flag so that servers follow the Redis cluster protocol and do not redirect requests when data requested is not local. In this case, smart Redis clients will operate as expected. Unlike most KV cache clusters, EloqKV clusters are strongly consistent. For example, if a node is dropped from the cluster due to a network partition, it is aware of the situation and can refuse to serve external requests until it rejoins.
We compare the performance of a single-node EloqKV instance with that of an EloqKV cluster to evaluate the cost of transparent redirection. In this assessment, EloqKV operates in pure memory mode, with persistent storage and transactional features disabled.
Hardware and Software Specification
Server Machine:
| Service type | Node type | Node count |
|---|---|---|
| EloqKV 0.7.4 | c7g.8xlarge | 1 |
| EloqKV 0.7.4 Cluster | c7g.8xlarge | 3 |
| Client - Memtier | c6gn.8xlarge | 3 |
Experiment:
We conducted performance benchmarks on a single-node EloqKV database under varying read-write ratios, utilizing a single memtier-benchmark client. The command used for this benchmarking is as follows:
memtier_benchmark -t 32 -c 16 -s $server_ip -p $server_port --distinct-client-seed --ratio=$ratio --key-prefix="kv_" --key-minimum=1 --key-maximum=5000000 --random-data --data-size=128 --hide-histogram --test-time=300
To assess the performance of a three-node EloqKV cluster, we utilized three memtier-benchmark clients in both regular and smart client modes. In regular client mode, users interact with the EloqKV cluster as if it were a single node without needing to consider where the keys are stored. The same memtier-benchmark command used for a single-node setup is applied to each regular client, with each client connecting to a different EloqKV node in the cluster.
For smart client mode, we ran memtier-benchmark in cluster mode with varying read-write ratios, using the following configuration:
memtier_benchmark -t 32 -c 16 --cluster-mode -s $server_ip1 -p $server_port1 -s $server_ip2 -p $server_port2 -s $server_ip3 -p $server_port3 --distinct-client-seed --ratio=$ratio --key-prefix="kv_" --key-minimum=1 --key-maximum=5000000 --random-data --data-size=128 --hide-histogram --test-time=300
Results
Below are the results of comparing the throughput of a single-node EloqKV instance with that of a three-node EloqKV cluster across various workloads. For the three-node cluster, we conducted benchmarks using both a regular client and a smart client. When using the regular client, EloqKV automatically redirects requests to other nodes if the requested key is not stored locally. In contrast, with the smart client, all requests are sent directly to the node that holds the key, based on the cached cluster configuration within the smart client.
X-axis: Represents the different workload types (read/write/mixed) used in the benchmark, simulating a range of real-world scenarios.
Y-axis: Measures the OPS (Operations Per Second).
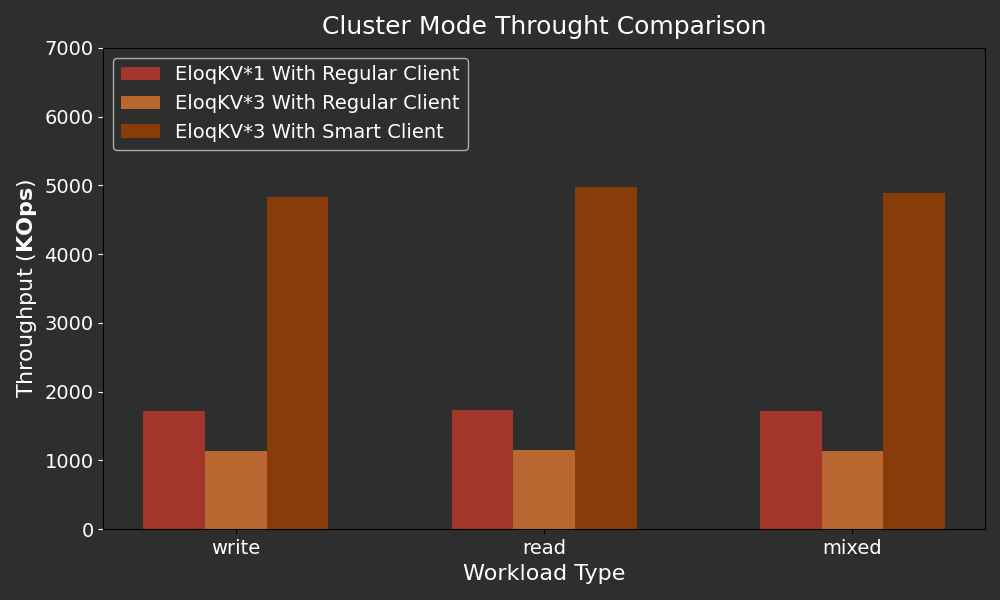
When using the regular client, the three-node EloqKV cluster has slightly lower throughput than the single-node instance due to the added network round trips and scheduling overhead caused by redirection. Despite this, the cluster still achieves over one million operations per second (OPS). Importantly, this requires no changes to application code, allowing developers to easily scale and overcome memory capacity limits without modifying their code or relying on smart clients.
Notice that a single Redis server can only support around 200K OPS (see our previous blog for a detailed analysis), thus we believe that EloqKV in cluster mode is already fast enough to support most application scenarios without relying on specially designed smart clients. Still, EloqKV does support smart clients. As expected, with a smart client, the three-node EloqKV cluster supports near three times the throughput of a single-node instance across various workloads. This highlights EloqKV's compatibility with smart clients.